Решающее дерево (Decision tree) — решение задачи обучения с учителем, основанный на том, как решает задачи прогнозирования человек. В общем случае — это k-ичное дерево с решающими правилами в нелистовых вершинах (узлах) и некотором заключении о целевой функции в листовых вершинах (прогнозом). Решающее правило — некоторая функция от объекта, позволяющее определить, в какую из дочерних вершин нужно поместить рассматриваем объект. В листовых вершинах могут находиться разные объекты: класс, который нужно присвоить попавшему туда объекту (в задаче классификации), вероятности классов (в задаче классификации), непосредственно значение целевой функции (задача регрессии).
Чаще всего на практике используются двоичные решающие деревья.
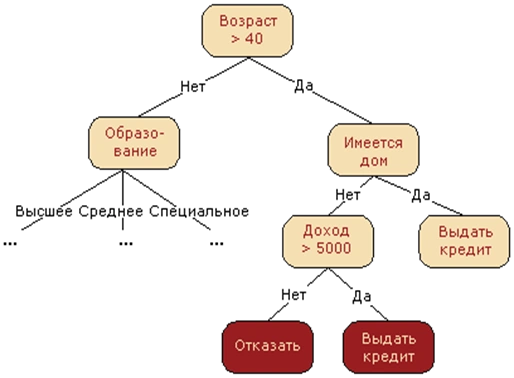
Алгоритм построения
В корне дерева — рассматриваем всю обучающую выборку.
- Проверить критерий останова алгоритма. Если он выполняется, выбрать для узла выдаваемый прогноз, что можно сделать несколькими способами.
- Иначе требуется разбить множество на несколько не пересекающихся. В общем случае в вершине задаётся решающее правило , принимающее некоторый диапазон значений. Этот диапазон разбивается на непересекающихся множеств объектов, , где — количество потомков у вершины, а каждое — это множество объектов, попавших в -го потомка.
- Множество в узле разбивается согласно выбранному правилу, для каждого узла алгоритм запускается рекурсивно.






Решающие правила
Чаще всего в качестве берут просто один из признаков, то есть .

Традиционные разбиения на диапазоны:
- для выбранных
- — по сути проверка угла.
- , где расстояние определено в некотором метрическом пространстве (например,).
- — предикаты, — скалярное произведение векторов.








В целом, взять можно любые решающие правила, но лучше — интерпретируемые, поскольку их легче настраивать. Особого смысла брать что-то сложнее предикатов нет, так как уже с их помощью можно получить дерево со 100%-й точностью на обучающейся выборке (но при этом и скорее всего переобучиться).
Выбор оптимального решающего правила
Считаем, что решаем задачу многоклассовой классификации или регрессии в -ичном дереве.

Обычно для построения дерева выбирается целое семейство решающих правил. Чтобы найти среди них оптимальное для каждого конкретного узла, требуется ввести некоторый критерий оптимальности. Для этого вводят некоторую меру измерения того, насколько разбросаны объекты (регрессия) или перемешаны классы (классификация) в некотором узле . Эта мера называется критерием информативности.

Затем для каждого варианта решающего правила подсчитывается мера того, насколько будут разбросаны объекты (регрессия) или перемешаны классы (классификация) при таком разбиении:
, где — на сколько узлов разбивается узел, — текущий узел, — узлы-потомки, получающиеся при выбранном разбиении, — количество объектов обучающей выборки, попадающие в потомок , — попавших в текущий узел, — объекты, попавшие в -ую вершину.






также называется Information gain, то есть сколько информации мы получим при таком разбиении. Для выбора решающего правила требуется взять argmax от неё по всевозможным признакам и параметрам семейства решающих правил. При таком взятии мы как раз и получим оптимальное разбиение множества объектов в текущей вершине.

Критерии останова
Лекции Соколова (6 стр.)
- Ограничение максимальной глубины дерева.
- Ограничение минимального числа объектов в листе.
- Ограничение максимального количества листьев в дереве.
- Останов в случае, если все объекты в вершине относятся к одному классу.
- Требование, что Information gain при дроблении улучшался как минимум
на процентов.

Стрижка
Для любой обучающей выборки существует дерево, которое не будет допускать на нём ни одной ошибки. Подобрать правильный критерий останова бывает затруднительно, поэтому прибегают к стрижке — строят дерево целиком, а затем начинают обрубать узлы с листов.
Стрижка по валидационной выборке
Лекции Воронцова, 63-я минута.
Рассмотрим бинарное решающее дерево на примере задачи классификации.
Выделим валидационной выборку порядка половины размера тренировочной (или можно, например, разделить выборку на 3 части, 2 из них оставить в качестве тренировочной, одну — в качестве валидационной).
Построим дерево по тренировочной выборке. Пропустим через построенное дерево валидационную выборку и рассмотрим любую внутреннюю вершину и её левую и правую вершины . Если до не дошло ни одного объекта из валидационной выборки, то говорим, что эта вершина (и все её поддеревья) незначимые и делаем из листовую (ставим в качестве предиката мажоритарный класс в этой вершине по тренировочной выборке). Если до дошли объекты из валидационной выборки, то рассмотрим следующие 3 величины:

- Число ошибок классификации поддеревом из вершины
- Число ошибок классификации поддеревом из вершины
- Число ошибок классификации поддеревом из вершины

Если в 1) Число ошибок классификации поддеревом из вершины равно 0, то значит делаем из листовую с соответствующим прогнозом для класса.
Выберем минимум из трёх вышеприведенных пунктов. В зависимости от того, какое из них минимально, сделаем соответственно следующие действия:
- Ничего не делать
- Заменить дерево из вершины деревом из вершины
- Заменить дерево из вершины деревом из вершины
Cost-complexity pruning
Семинары Соколова, стр. 6 – 7.
Обозначим дерево, полученное в результате работы жадного алгоритма, через . Поскольку в каждом из листьев находятся объекты только одного класса, значение функционала будет минимально на самом дереве (среди всех поддеревьев). Однако данный функционал характеризует лишь качество дерева на обучающей выборке, и чрезмерная подгонка под нее может привести к переобучению. Чтобы преодолеть эту проблему, введем новый функционал , представляющий собой сумму исходного функционала и штрафа за размер дерева:




где — число листьев в поддереве , а — параметр. Это один из примеров регуляризованных критериев качества , которые ищут баланс между качеством классификации обучающей выборки и сложностью построенной модели. В дальнейшем мы много раз будем сталкиваться с такими критериями. Можно показать, что существует последовательность вложенных деревьев с одинаковыми корнями: , (здесь — тривиальное дерево, состоящее из корня дерева ), в которой каждое дерево минимизирует критерий для из интервала , причем . Эту последовательность можно достаточно эффективно найти путем обхода дерева. Далее из нее выбирается оптимальное дерево по отложенной выборке или с помощью кросс-валидации.










Выбор прогноза в листе
- Самый простой способ — взять самый часто встречающийся класс среди объектов обучающей выборки, попавших в этот лист, для классификации или среднее целевых функций этих объектов для регрессии.
- В задачах классификации c классами в листе также можно хранить вероятности классов — например, по классической вероятности: , где — классы. Более подробно, как в таком случае выбирать класс, описано в обработке пропусков



- Если задана матрица штрафов, то есть в случае несимметричных потерь, можно минимизировать штраф и взять в качестве класса в листе :

, где — элементы матрицы штрафов.


- В регрессии — использовать функцию потерь, то есть:

Выбор функции потерь в общем случае является параметром алгоритма.
Прогнозирование
Для случая отсутствия пропущенных значений. Алгоритм: начиная с корня, применить к новому объекту решающее правило. Таким образом определяется, в какой потомок объект должен "попасть", и рекурсивно запустить этот процесс для него.
Сложность прогнозирования для одного объекта для полностью построенного дерева — , где — высота дерева. Вообще говоря, дерево может быть несбалансированным, поэтому оценка в , где — размер тренировочной выборки, не гарантируется.




Метод обработки пропущенных значений
Пропуск пропущенных значений
Лекции Воронцова, 59-я минута.
| Сергей Иванов: Вроде в билетах этого нет, но вполне вопрос. |
При обучении дерева объекты с пропущенными значениями у признака, по которому идет разбиение, игнорируются:

При построении прогноза при необходимости разбить подвыборку в вершине по отсутствующему признаку происходит следующая процедура: будем как бы предполагать, что этот признак принимает случайное значение. Определим по обучающей выборке вероятности, с которой новый объект попадёт к каждому потомку — . Затем отправим объект независимо к каждому потомку, получим прогнозы . В случае регрессии это будут непосредственно значения целевой функции, в случае классификации — вероятности принадлежности какому-то зафиксированному классу (который, как будет видно ниже, надо перебирать):




Дальше можно поступать образом, схожим с выбором прогноза в листе: так, для регрессии можно просто объединить отклики с вероятностями в качестве весов, .

Пусть — корень дерева. В случае классификации


Такой алгоритм работы с пропущенными значениями используется в ID3, C4.5.
Суррогатные разбиения
Находим другой признак, по которому разбиение будет максимально похожим. Выкидываем те объекты, по которому по данному признаку есть пропущенные значения, делаем разбиение. Ищем другой признак (видимо, предполагаем, что по нему нет пропущенных значений, либо сразу выкидывать объекты с пропущенными значениями и по первому приведенному признаку и по второму), берем максимально похожее разбиение на изначальное. Например, можно сравнивать как можно большее пересечение левых и правых поддеревьев (в случае бинарного дерева).
Такой алгоритм работы с пропущенными значениями используется в CART
Работа с категориальными признаками
 |
Эта статья нуждается в структуризации!
|
| Сергей Иванов: Возможно, часть информации здесь не относится к деревьям; следует вынести в отдельную статью по работе с категориальными признаками |
One-hot кодирование
Из вершины делаем столько детей, сколько уникальных значений у категориального признака.
При таком подходе размер дерева увеличивается увеличивается риск переобучения.

Перевод категориальных в вещественные
Семинары Соколова, стр. 8
Пусть категориальный признак имеет множество значений . Разобьем множество значений на дванепересекающихся подмножества: , и определим предикат как индикатор попадания в первое подмножество: . Таким образом, объект будет попадать в левое поддерево, если признак попадает в множество , и в первоеподдерево в противном случае. Основная проблема заключается в том, что для построения оптимального предиката нужно перебрать вариантов разбиения,что может быть не вполне возможным.



![{\displaystyle \beta (x)=\mathbb {I} [x_{j}\in Q_{1}]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/ac672b387361765678dab5f31c8b6f38f37e2c97)


Оказывается, можно обойтись без полного перебора в случаях с бинарной классификацией и регрессией. Обозначим через множество объектов, которые попали в вершину и у которых -й признак имеет значение ; через обозначим количество таких объектов. В случае с бинарной классификацией упорядочим все значения категориально- го признака на основе того, какая доля объектов с таким значением имеет класс :






![{\displaystyle {\dfrac {1}{N_{m}(u_{(1)})}}\sum _{x_{i}\in R_{m}(u_{(1)})}\mathbb {I} [y_{i}=+1]\leq \dots \leq {\dfrac {1}{N_{m}(u_{(q)})}}\sum _{x_{i}\in R_{m}(u_{(q)})}\mathbb {I} [y_{i}=+1]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/64387a4154f12ad627d0f42bae695bff3e3dfb0d)
после чего заменим категорию на число , и будем искать разбиение как для вещественного признака. Можно показать, что если искать оптимальное разбиение по критерию Джини или энтропийному критерию, то мы получим такое же разбиение, как и при переборе по всем возможным вариантам. Для задачи регрессии с MSE-функционалом это тоже будет верно, если упорядочивать значения признака по среднему ответу объектов с таким значением:


{kind=link}
{kind=link}
CART-деревья
Реализация решающего дерева — за подробностями милости просим сюда.