Liebeann (обсуждение | вклад) мНет описания правки Метка: rte-source |
Liebeann (обсуждение | вклад) мНет описания правки Метка: rte-source |
||
| Строка 1: | Строка 1: | ||
| − | '''Решающее дерево (Decision tree) ''' — решение задачи [[Обучение с учителем (Supervised learning)|обучения с учителем]], основанный на том, как решает задачи прогнозирования человек. В общем случае — это k-ичное дерево с ''решающими правилами'' в нелистовых вершинах (узлах) и некотором заключении о целевой функции в листовых вершинах (прогнозом). ''Решающее правило'' — некоторая функция от объекта, позволяющее определить, в какую из дочерних вершин нужно поместить рассматриваем объект. В листовых вершинах могут находиться разные объекты: класс, который нужно присвоить попавшему туда объекту (в задаче классификации), вероятности классов (в задаче классификации), непосредственно значение целевой функции (задача регрессии). |
+ | '''Решающее дерево (Decision tree) ''' — решение задачи [[Обучение с учителем (Supervised learning)|обучения с учителем]], основанный на том, как решает задачи прогнозирования человек. В общем случае — это k-ичное дерево с ''решающими правилами'' в нелистовых вершинах (узлах) и некотором заключении о целевой функции в листовых вершинах (''прогнозом''). ''Решающее правило'' — некоторая функция от объекта, позволяющее определить, в какую из дочерних вершин нужно поместить рассматриваем объект. В листовых вершинах могут находиться разные объекты: класс, который нужно присвоить попавшему туда объекту (в задаче классификации), вероятности классов (в задаче классификации), непосредственно значение целевой функции (задача регрессии). |
Чаще всего на практике используются '''двоичные решающие деревья'''. |
Чаще всего на практике используются '''двоичные решающие деревья'''. |
||
| Строка 21: | Строка 21: | ||
* <math>S_t(j) = \left \{x \in \mathbb{X}: h_j \le x^{i(t)} \le h_{j+1}\right \}</math> для выбранных <math>h_1, \dots, h_{j+1}</math> |
* <math>S_t(j) = \left \{x \in \mathbb{X}: h_j \le x^{i(t)} \le h_{j+1}\right \}</math> для выбранных <math>h_1, \dots, h_{j+1}</math> |
||
* <math>S_t(1) = \left \{x \in \mathbb{X}: \langle x,v \rangle \le 0\right \}; S_t(2) = \left \{x \in \mathbb{X}: \langle x,v \rangle > 0\right \}</math> — по сути проверка угла. |
* <math>S_t(1) = \left \{x \in \mathbb{X}: \langle x,v \rangle \le 0\right \}; S_t(2) = \left \{x \in \mathbb{X}: \langle x,v \rangle > 0\right \}</math> — по сути проверка угла. |
||
| − | * <math>S_t(1) = \left \{x \in \mathbb{X}: \rho (x, x_0) \le h\right \}; S_t(2) = \left\{x \in \mathbb{X}: \rho (x, x_0) > h\right \}</math>, где расстояние <math>\rho</math> определено в некотором метрическом пространстве (например,<math>\rho (x, y) = |x - y|</math>. |
+ | * <math>S_t(1) = \left \{x \in \mathbb{X}: \rho (x, x_0) \le h\right \}; S_t(2) = \left\{x \in \mathbb{X}: \rho (x, x_0) > h\right \}</math>, где расстояние <math>\rho</math> определено в некотором метрическом пространстве (например,<math>\rho (x, y) = |x - y|</math>). |
* <math>S_t(1) = \left \{x \in \mathbb{X}: x^{i(t)} \le h\right \}; S_t(2) = \left \{x \in \mathbb{X}: x^{i(t)} > h\right \}</math> — '''предикаты''', <math>\langle x, v \rangle </math> — скалярное произведение векторов. |
* <math>S_t(1) = \left \{x \in \mathbb{X}: x^{i(t)} \le h\right \}; S_t(2) = \left \{x \in \mathbb{X}: x^{i(t)} > h\right \}</math> — '''предикаты''', <math>\langle x, v \rangle </math> — скалярное произведение векторов. |
||
Версия от 14:06, 6 января 2017
Решающее дерево (Decision tree) — решение задачи обучения с учителем, основанный на том, как решает задачи прогнозирования человек. В общем случае — это k-ичное дерево с решающими правилами в нелистовых вершинах (узлах) и некотором заключении о целевой функции в листовых вершинах (прогнозом). Решающее правило — некоторая функция от объекта, позволяющее определить, в какую из дочерних вершин нужно поместить рассматриваем объект. В листовых вершинах могут находиться разные объекты: класс, который нужно присвоить попавшему туда объекту (в задаче классификации), вероятности классов (в задаче классификации), непосредственно значение целевой функции (задача регрессии).
Чаще всего на практике используются двоичные решающие деревья.
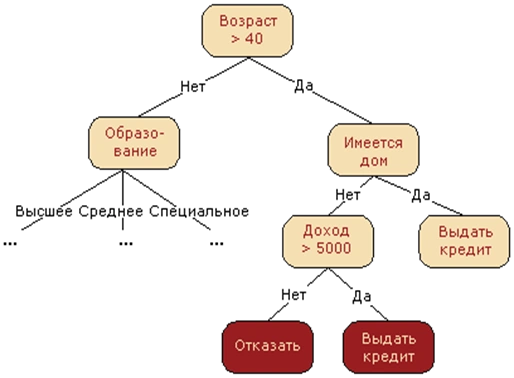
Идея

немного Соколовщины и интуиции
Алгоритм построения
В корне дерева — рассматриваем всю обучающую выборку.
- Проверить критерий останова алгоритма. Если он выполняется, выбрать для узла выдаваемый прогноз, что можно сделать несколькими способами.
- Иначе требуется разбить множество на несколько не пересекающихся. В общем случае в вершине задаётся решающее правило , принимающее некоторый диапазон значений. Этот диапазон разбивается на непересекающихся множеств объектов, , где — количество потомков у вершины, а каждое — это множество объектов, попавших в -го потомка.
- Множество в узле разбивается согласно выбранному правилу, для каждого узла алгоритм запускается рекурсивно.






Решающие правила
Чаще всего в качестве берут просто один из признаков, то есть .

Традиционные разбиения на диапазоны:
- для выбранных
- — по сути проверка угла.
- , где расстояние определено в некотором метрическом пространстве (например,).
- — предикаты, — скалярное произведение векторов.








В целом, взять можно любые решающие правила, но лучше — интерпретируемые, поскольку их легче настраивать. Особого смысла брать что-то сложнее предикатов нет, так как уже с их помощью можно получить дерево со 100%-й точностью на обучающейся выборке (но при этом и скорее всего переобучиться).
Выбор оптимального решающего правила
Считаем, что решаем задачу многоклассовой классификации или регрессии в -ичном дереве.

Обычно для построения дерева выбирается целое семейство решающих правил. Чтобы найти среди них оптимальное для каждого конкретного узла, требуется ввести некоторый критерий оптимальности. Для этого вводят некоторую меру измерения того, насколько разбросаны объекты (регрессия) или перемешаны классы (классификация) в некотором узле . Эта мера называется критерием информативности.

Затем для каждого варианта решающего правила подсчитывается мера того, насколько будут разбросаны объекты (регрессия) или перемешаны классы (классификация) при таком разбиении:
, где — на сколько узлов разбивается узел, — текущий узел, — узлы-потомки, получающиеся при выбранном разбиении, — количество объектов обучающей выборки, попадающие в потомок , — попавших в текущий узел, — объекты, попавшие в -ую вершину.






также называется Information gain, то есть сколько информации мы получим при таком разбиении. Для выбора решающего правила требуется взять argmax от неё по всевозможным признакам и параметрам семейства решающих правил. При таком взятии мы как раз и получим оптимальное разбиение множества объектов в текущей вершине.

Критерии останова
Лекции Соколова (6 стр.)
- Ограничение максимальной глубины дерева.
- Ограничение минимального числа объектов в листе.
- Ограничение максимального количества листьев в дереве.
- Останов в случае, если все объекты в вершине относятся к одному классу.
- Требование, что Information gain при дроблении улучшался как минимум
на процентов.

Выбор прогноза в листе
Самый простой способ — взять самый часто встречающийся класс среди объектов обучающей выборки, попавших в этот лист, для классификации или среднее целевых функций этих объектов для регрессии.
В задачах классификации c классами в листе также можно хранить вероятности классов — например, по классической вероятности: , где — классы. Более подробно, как в таком случае выбирать класс, описано в обработке пропусков



Если задана матрица штрафов, то есть в случае несимметричных потерь, можно минимизировать штраф и взять в качестве класса в листе : , где — элементы матрицы штрафов.



В регрессии — использовать функцию потерь, то есть:

Выбор функции потерь в общем случае является параметром алгоритма.
Прогнозирование
Для случая отсутствия пропущенных значений. Алгоритм: начиная с корня, применить к новому объекту решающее правило. Таким образом определяется, в какой потомок объект должен "попасть", и рекурсивно запустить этот процесс для него.
Сложность прогнозирования для одного объекта для полностью построенного дерева — , где — высота дерева. Вообще говоря, дерево может быть несбалансированным, поэтому оценка в , где — размер тренировочной выборки, не гарантируется.




Метод обработки пропущенных значений
Лекции Воронцова, 59-я минута.
| Сергей Иванов: Вроде в билетах этого нет, но вполне вопрос. |
При обучении дерева объекты с пропущенными значениями у признака, по которому идет разбиение, игнорируются:

При построении прогноза при необходимости разбить подвыборку в вершине по отсутствующему признаку происходит следующая процедура: будем как бы предполагать, что этот признак принимает случайное значение. Определим по обучающей выборке вероятности, с которой новый объект попадёт к каждому потомку — . Затем отправим объект независимо к каждому потомку, получим прогнозы . В случае регрессии это будут непосредственно значения целевой функции, в случае классификации — вероятности принадлежности какому-то зафиксированному классу (который, как будет видно ниже, надо перебирать):




Дальше можно поступать образом, схожим с выбором прогноза в листе: так, для регрессии можно просто объединить отклики с вероятностями в качестве весов, .

Пусть — корень дерева. В случае классификации


{kind=link}
CART-деревья
Реализация решающего дерева — за подробностями милости просим сюда.
Обобщающая способность деревьев
Для любой обучающей выборки существует дерево, которое не будет допускать на нём ни одной ошибки. Подобрать правильный критерий останова бывает затруднительно, поэтому прибегают к стрижке — строят дерево целиком, а затем начинают обрубать узлы с листов. Подробнее.